数据分析技术先行 如何提升数据处理与存储服务中的准确性
在当今数据驱动的商业环境中,数据分析的价值日益凸显,而这一切都建立在高质量、准确的数据基础之上。数据处理与存储服务作为数据分析流程的基石,其准确性直接决定了后续洞察的可靠性与决策的有效性。因此,秉持“技术先行”的理念,系统性地提升数据处理各环节的准确性,已成为企业数字化转型的核心课题。
一、 源头治理:构建高质量的数据采集与接入体系
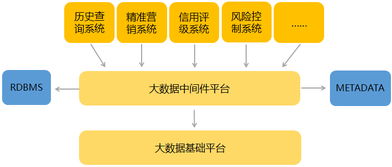
数据准确性始于源头。需明确数据标准与规范,在数据采集端(如传感器、业务系统、用户交互界面)就实施验证规则,例如格式检查、范围校验、唯一性约束等。对于多源异构数据的接入,应采用统一的数据集成平台或ETL工具,确保数据在抽取、转换过程中语义一致,避免信息失真。技术手段如数据血缘追踪和数据质量监控看板,能帮助快速定位并修正采集阶段的异常。
二、 过程精炼:强化数据清洗、转换与计算的可靠性
数据处理阶段是提升准确性的主战场。
- 智能清洗:运用规则引擎与机器学习算法,自动识别并处理缺失值、异常值、重复记录和不一致数据。例如,通过模式识别修正错误录入,或基于统计方法合理填充缺失值。
- 精准转换:在数据转换与聚合过程中,确保业务逻辑的准确编码。使用版本控制的代码或可视化工作流来管理转换规则,并进行充分的单元测试与回归测试,防止逻辑错误引入偏差。
- 可验证计算:对于关键指标计算,引入交叉验证机制。例如,通过不同路径或方法计算同一指标,对比结果以验证一致性。记录完整的数据衍生过程,确保计算可审计、可复现。
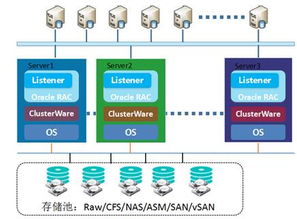
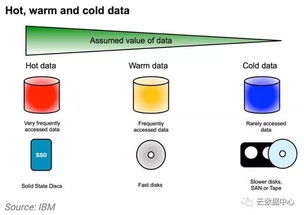
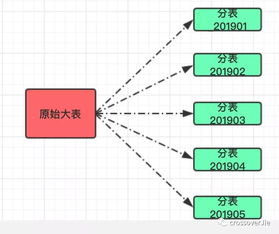
三、 存储保障:设计高保真、可追溯的数据存储架构
可靠的数据存储服务是维持数据准确性的稳定后方。
- 架构选择:根据数据特性(如结构化、非结构化)和访问模式,选择合适的存储方案(如关系型数据库、数据湖、数据仓库)。实施严格的数据模式管理(Schema Management),避免结构混乱导致的信息丢失或错误解读。
- 完整性约束:在数据库层面充分利用主键、外键、检查约束等机制,保障数据的实体完整性与参照完整性。
- 版本与追溯:对关键数据或频繁更新的数据,考虑引入数据版本控制或缓慢变化维技术,完整记录数据的历史状态变化,确保在任何时间点都能追溯到准确的数据快照,并支持对数据变更影响的分析。
四、 持续监控与闭环优化:建立数据准确性的长效机制
提升准确性并非一劳永逸,而是一个持续的过程。
- 全景监控:建立覆盖全链路的数据质量监控体系,定义准确性、完整性、一致性、时效性等核心质量指标,并设置自动告警阈值。利用监控仪表盘实时可视化数据健康状态。
- 闭环治理:建立从问题发现、根因分析、任务派发到修复验证的数据质量闭环治理流程。将数据质量问题单纳入日常运维,明确责任主体与处理时效。
- 文化培育:在组织内倡导“数据质量人人有责”的文化。通过培训提升全员的数据素养,让业务人员与技术团队紧密协作,共同定义和维护高质量的数据标准。
在数据分析技术先行的时代,数据处理与存储服务的准确性是释放数据价值的生命线。它需要从前端的采集规范、中端的处理逻辑、后端的存储架构,到全程的监控治理,进行全方位的技术加固与流程设计。通过构建这样一个系统化、自动化、智能化的数据准确性保障体系,企业才能确保其数据资产真实可信,从而为精准分析和智能决策奠定坚不可摧的基石,最终在激烈的市场竞争中赢得先机。